



Why your AWS Data Lake Transformation Needs a Lakehouse
- October 04, 2021
What makes a lake better? Having a house to set sail from and come back to. Lakehouse architecture makes a data lake more integrated with data stores especially for data warehouses. This increases data lake accessibility, lowers overall complexity, makes governing clearer and more direct, and reduces the cost for your suite of applications by centralizing the gravity of the data.
Data Lake Storage Classes
At the core of a lakehouse is the lake; in AWS, the lake is Amazon Simple Storage Service (Amazon S3). Amazon S3 has varying levels of storage classes to match the temperature of your data access. Keep in mind some cold storage classes are not capable of fully leveraging the features of a data lakehouse. Check out this article on data migration for how to move different types of data into Amazon S3. You can even use similar patterns to continually hydrate your lake within the cloud.
Access frequency represents hot and cold data, with frequent being hot while archive is cold.

Image of Amazon S3 Storage Classes courtesy of AWS Activate-Next Workshop
Lakehouse catalog
The foundation of your lakehouse is only as strong as the quality of the catalog which keeps it standing. In this article we will use the AWS Glue Data Catalog as our catalog. However, regardless of the catalog you choose, it’s imperative that it serves as the single source of truth. A cracked foundation is not a strong foundation. When committing to a catalog stick to it.
The AWS Glue Data Catalog easily integrates with many other services on the platform, while being serverless and scalable. In addition, it is compatible with anything that supports a hive metastore, should you wish to use third party software like DataBricks or Snowflake.
Example workflow for AWS Glue Crawlers
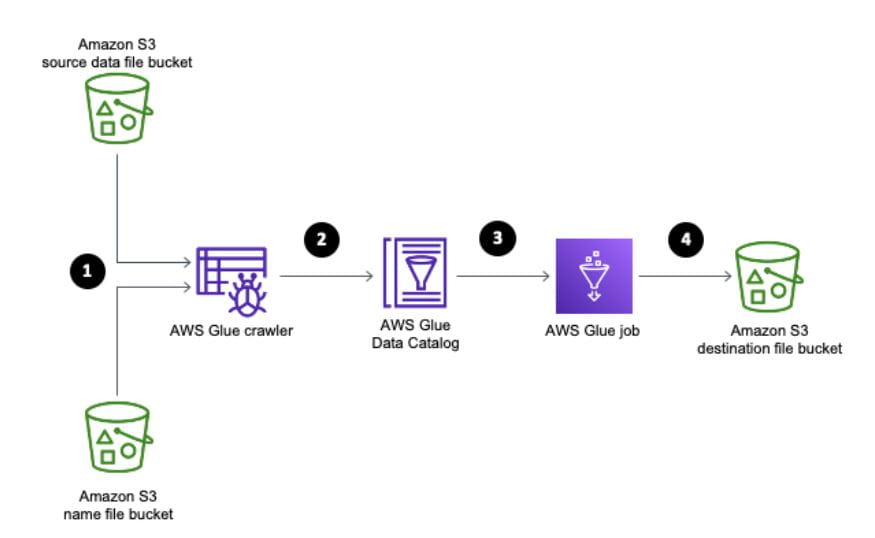
Image of Glue Crawler workflow courtesy of aws.amazon.com
How to populate data into an AWS Glue Data Catalog
Start by crawling your data for your AWS Glue databases. AWS Glue crawlers take the data you have stored in your Amazon S3 buckets and determine the table schema for the database you defined for the crawler. Normal functions like updates and deletes can be done by using pyspark in AWS Glue jobs. Versioning of crawled schema can be done through the AWS Glue Schema Registry. Finally, schema validation can be done a few different ways within AWS Glue. You can use the AWS Glue Schema Registry, use classifiers on your crawlers, or use resolve choice through the AWSS Glue library with pyspark and do a comparison on the schema before data preparation.
Lakehouse governance and evolution
Once the catalog is populated, how does one govern its contents? AWS Lake Formation (Learn more about AWS service for building data lakes here) is unlike other governing services because it is offered for free with the AWS Glue Data Catalog and includes super fine-grain controls that makes catalog access incredibly consistent and scalable. AWS Lake Formation gives you ACID transactions with SAML-backed authentication that extends as far as the cell level of the dataset. No more duplication of sensitive data and no more complicated access patterns. Everyone can have access to all the same data at the same time with their SAML identity provider credentials or systems through IAM roles at no additional cost.
Overall topology of discussion:
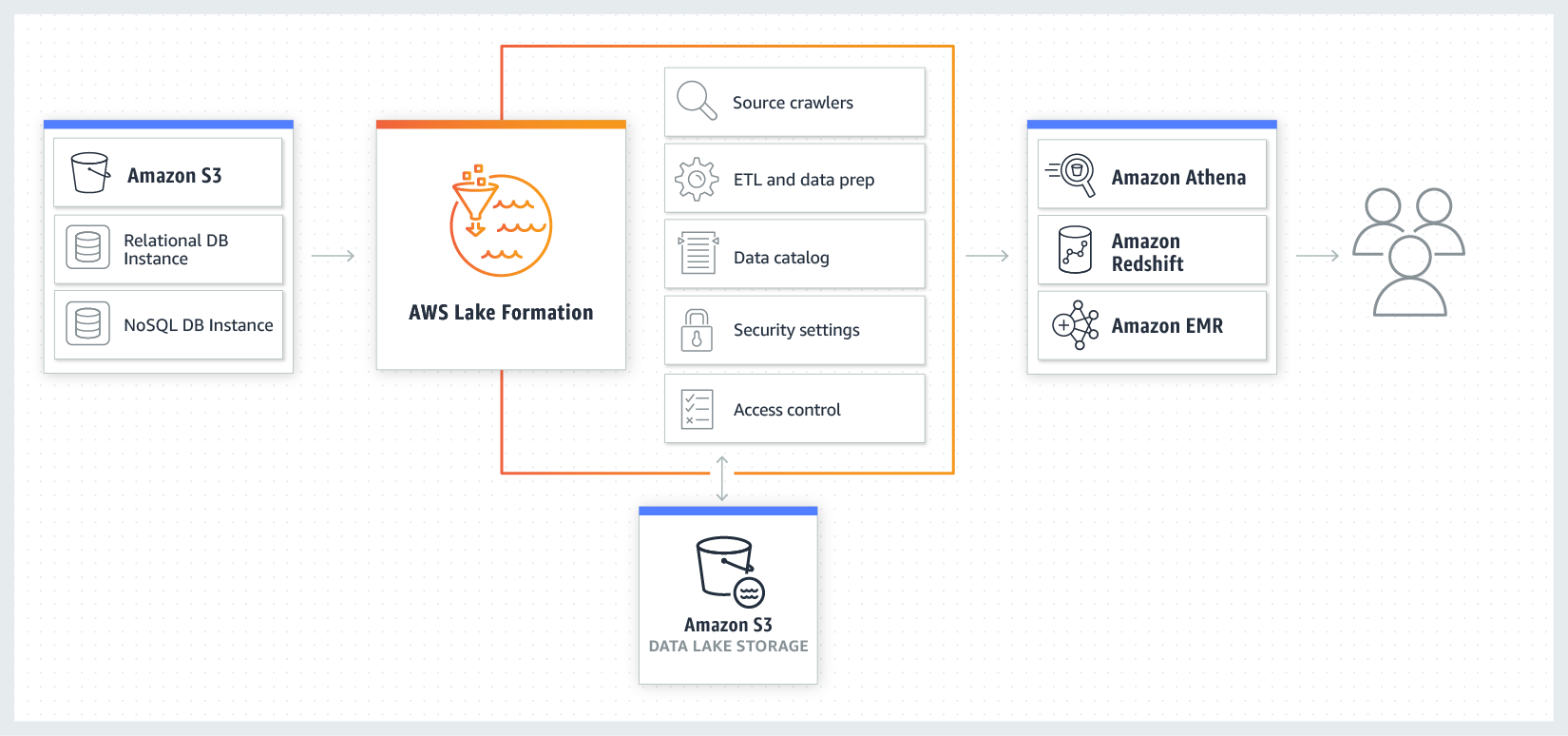
Image of AWS Lake Formation integration courtesy of aws.amazon.com
For all your BI or visualization tools, it is now as simple as connecting to Amazon Athena through JDBC / ODBC and using your normal SAML backed credentials to run federated queries against your data lakehouse.
Through the data lakehouse, you can start to achieve turnkey data democratization at any budget and scale. All of this and more is what AWS offers and to top it off, everything mentioned is serverless which reduces overhead and complexity. Go try it out in a development capacity and save in your lower environments while reserving more dedicated compute (if necessary) like Amazon EMR and Amazon Redshift for your production workload. Enjoy the water!
- What is a Data Lakehouse?
- AWS Data Lake Solution Addresses Rapid Data Expansion
- Build a Best Practice AWS Data Lake Faster with AWS Lake Formation
Need help determining if a data lakehouse architecture is a fit for your needs? .
Subscribe to our blog