



Single Node OpenStack Installation | Cloud Computing
- March 05, 2014
Many organizations, especially those that are making heavy use of modernized services in the cloud are considering or have implemented Site Reliability Engineers to manage their application ecosystems. But what are Site Reliability Engineers?
Site Reliability Engineering, or SRE for short, is the practice of product reliability delivered by incorporating software engineering methods to manage application ecosystems, to solve operations issues and to provide toil-reducing automation. Fundamentally, the SRE role is focused on the following areas, according to the seminal book Site Reliability Engineering: How Google Runs Production Systems by Petoff, Murphy, Beyer, and Jones:
- Availability
- Latency
- Performance
- Efficiency
- Change Management
- Monitoring
- Emergency Planning and
- Capacity Planning
These SRE responsibilities, or tenets, are achieved primarily through automation.
SRE Origins
The name Site Reliability Engineering was originally coined in 2003 by Ben Traynor, the VP of Engineering at Google. Traynor’s intent was to use engineers with software expertise to manage IT operations. Google and Traynor implemented the concept of SRE before the DevOps movement was started in 2007-2008 and continued with this concept through current times. The popularity of SRE rose as organizations such as Netflix, Facebook and Uber adopted the concept, as covered in this blog about why Google invented the SRE role.
The practice of SRE can be very effective if properly implemented and managed but many organizations struggle to reap the intended benefits of SRE. This problem is similar to the issues that organizations encounter when implementing DevOps practices. Good intentions do not always guarantee success. There are many reasons for these struggles and chief among them is the necessity for purity in the SRE practice and the required organizational support of the construct. No two organizations define SRE in the same way. The needs of each organization can vary. So, implementation of an SRE practice may vary from organization to organization, but the core tenants should be adhered to if the implementation is to be successful. A top problem encountered is allowing the SRE team the autonomy to focus on reliability. It is easy for organizations to lean excessively to the needs of development functions or to that of IT operations. The SRE role is a fine balance of the two concerns and must be allowed to operate in this way to be effective. To be successful, the SRE team should demonstrate value to both the product team (Development) and the platform team (IT operations).
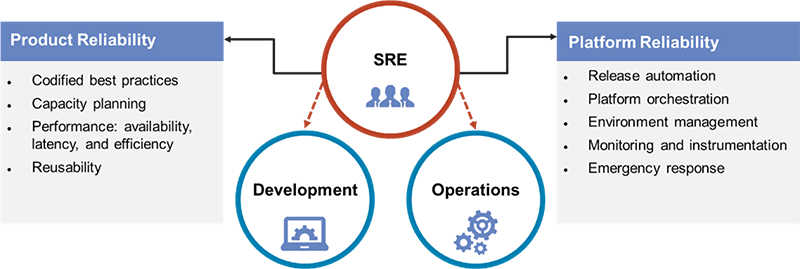
SRE: A Balancing Act
Demonstrating value in an incremental fashion is a highly effective way for an SRE practice to maintain effectiveness but the nature of SRE will be a mix of planned and unplanned activities. Therefore, the SRE team needs to ensure that it can prioritize the unplanned activities while adding value through planned work, such as automation development. If properly implemented there should be a blend of these two activities.
Some suggest up to 50% of an SRE’s time should be reserved to allow ample time for software engineering work (Automation). Maintaining this balance and prioritizing unplanned work is an effort that resembles a software development project with a bit of reactive work sprinkled in. This is where an Agile method has its strengths.
Introducing the Agile Pod Concept
One Agile construct that can meet the needs described above and solve a few other problems along the way is the “Agile Pod” construct. A Pod, which is an acronym for Product Oriented Delivery, is an operating model that enables an extremely collaborative and self-organizing team to deliver value in a highly focused manner. The early concept of Agile Pods (squads & tribes) began in what became known as the Spotify Model. The Spotify Model was first introduced in October 2012 when Henrik Kniberg and Anders Ivarsson published the white paper Scaling Agile @ Spotify with Tribes, Squads, Chapters & Guilds.
Like the construct of Site Reliability Engineering, no two organizations will define Agile Pods in the same way. And like the SRE construct, the key to implementation of Agile Pods is staying true to the core features of Agile Pods.
Agile Pod Core Features
First, and foremost, the Agile Pod is Autonomous. Each Pod decides how it will achieve creative, strategic and production goals. Second, the Pod is cross functional and multi-disciplinary. Each Pod has a Pod leader, full-time members, and part-time specialists. Third, they are aligned with business goals. The Pod is focused on the goals of the business, not on a specific department or product. Fourth, the Pod has between three and nine members to remain Agile. If the Pod becomes too large, agility will be a challenge. Fifth, the Pod develops its skills maturity over time. This requires patience as it may take some time for the SRE Pod to find its rhythm. Sixth, the Pod practices Agile methods to incrementally deliver value to its clients.
| SRE Agile Pod Core Features |
|---|
| 1) Autonomous in nature |
| 2) Cross functional & multi-disciplinary |
| 3) Formed and aligned with the business |
| 4) 3-9 members in size |
| 5) Develops maturity over time |
| 6) Agile in its practices |
When combined, an SRE practice organized in an Agile Pod is an effective combination that can bring continual incremental value to the business. The part-time aspect of the Agile Pod serves the SRE function quite well as the nature of the work of an SRE team may require only part-time skills for some practitioners while demanding full-time for others.
An example of an SRE Agile Pod may include a Pod leader, a fulltime, or part time Agilist coach, full-time SRE members and part time technical specialists’ members of the Pod. The part-time specialists could be a number of specialty skills such as security engineers, data pipeline specialists, IoT software engineers, etc. The Agilist is an addition used by NTT DATA to reinforce the Agile nature of the Pod and to coach the highly technical and occasionally transient resources in the Agile method. The Pod may choose its own Agile methodology, be it Kanban or Scrum, but delivering incremental features is key to the success of the Pod. The autonomous nature of the Pod allows the Pod to choose which method works best for them.
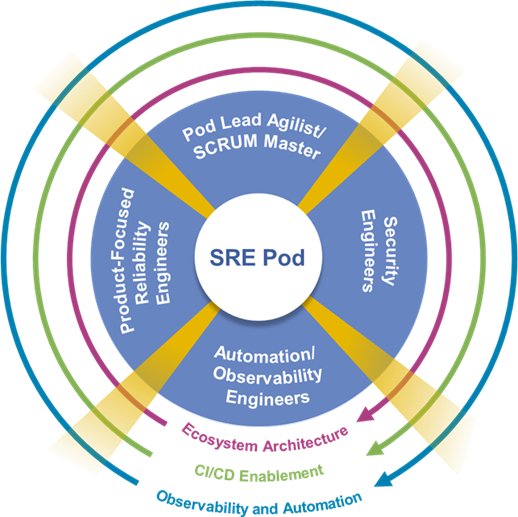
SRE Pods Demonstrating Value
Measuring value is also important to the success of SRE Pods. Key performance indicators (KPIs) will highlight areas of focus for the SRE Pod and should be presented to the business as a demonstration of value. Features such as new automation or observability dashboards can be evident to the business but some of the greatest value (i.e. greater reliability, higher release velocity or reduced toil) are better measured through KPIs and reported to the business.
There is no doubt that Site Reliability Engineering can bring high value to organizations adopting modernized cloud services if properly implemented. The extent of the value depends on the efficacy of the SRE practice, which in turn, depends on staying true to the core tenets of SRE. A strong iterative methodology that places importance on autonomy and delivering incremental value can enable the SRE practice to deliver on the promise of high value. The Agile Pod model is, in my opinion, the right fit for SRE.
To better understand SRE and similar concepts about enabling cloud-enabled digital transformation, please subscribe to the NTT DATA Tech Blog and we’ll send you occasional emails on interesting news, topics and stories like this.
Subscribe to our blog