



Busting the Cloud Bursting Myth
- May 27, 2020
The C-Suite likes to think of cloud bursting like the magic waistband on my Thanksgiving pants — it dynamically expands to support me as I consume more and retracts once things return to business as usual. We all know that the pants don't magically hide my Thanksgiving glut, (and I'll need to do some extra miles to work it off). Yet, the myth exists that there are no similar challenges when it comes to cloud bursting. While the cloud offers a myriad of benefits for HPC workloads, cloud bursting is often not the best path to achieve them. In today's article I'll walk you through why that's the case and share in conclusion the best path to achieving cloud upside.
The origin of the myth
Most HPC shops have a target CPU utilization against which they manage capacity. There’s a capacity planning process wherein the grid team collects internal customer CPU demand roadmaps for the next 6-12 months and then they rationalize that demand against their budget. It’s usually a lengthy, labor-intensive process that in the end yields utilization graphs like this:
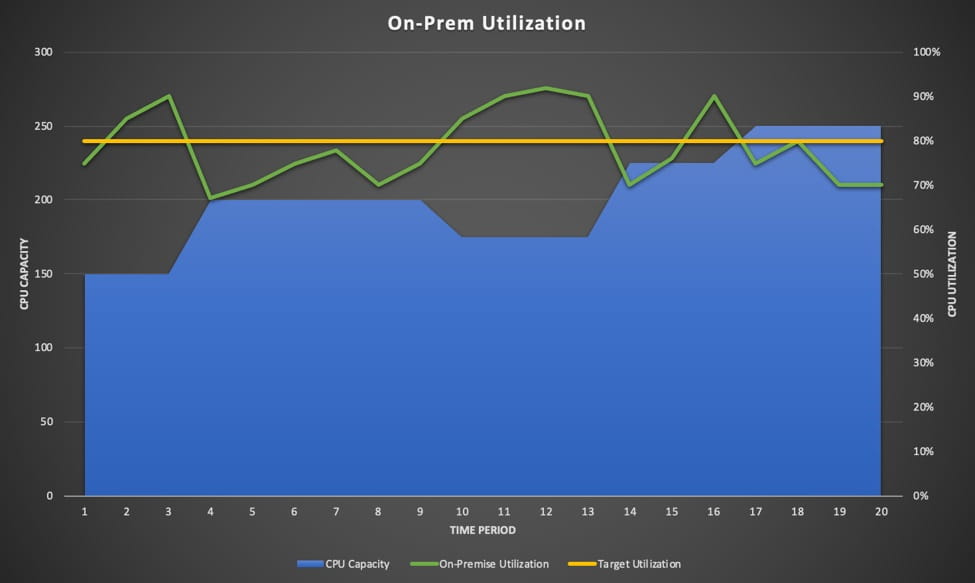
There are a few things to note about this graph:
- Target utilization of 80% is a hit-and-miss affair.
- Demand spikes above target utilization mean one thing — increased pend times for your end users and lots of calls to remind you about it.
- Between period 9 and 10 there’s a dip in capacity even though demand is increasing. This usually happens because of budget constraints colliding with unforeseen demand. Notice how demand keeps rising even though capacity is lower before a sudden jump in capacity. That’s the cycle time of an emergency capital request.
One of the promises of the cloud is the ability to dynamically offload workload while keeping your on-premises utilization at targeted levels. Every C-Level Exec sees this picture in his or her head when they hear about the concept:
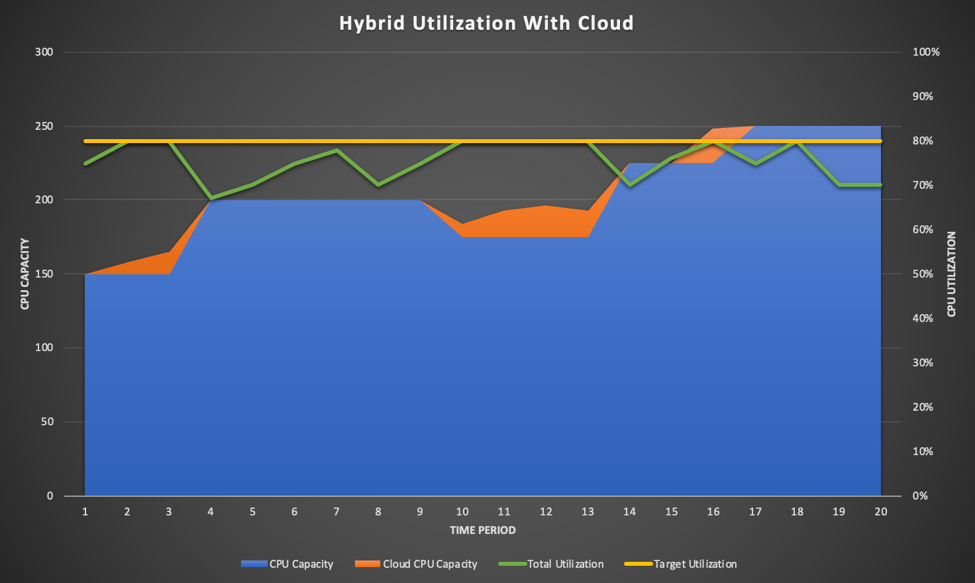
This is the same demand curve as the above graph. The orange sections represent dynamic cloud capacity brought online to manage pend times while keeping on-premises utilization at the target level of 80%.
On the surface, this seems like an ideal situation! Make small, incremental investments in cloud so that you can perform hybrid cloud bursting!
Unfortunately, this is not as easy as it sounds.
The Challenge Behind Cloud Bursting
There are four primary challenges with this C-Suite vision of hybrid cloud — each of which I’ll break down, so you are armed to have this conversation with your management and peers. And, as promised, we’ll bring it all together with the best approach for maximizing cloud benefits for your HPC workloads.
- Data synchronization
The first, and most obvious, challenge is the amount of data involved in the jobs you need to burst. Some jobs, such as simulations, require a small amount of data in order to run properly. Others can require hundreds of gigabytes before they can begin. In either case, you will need some mechanism of data synchronization to fully realize the hybrid dream.
Data synchronization requires you to copy the data into a known location for use in the cloud. The best-case scenario is that you have full control of your workflow and can modify it so that it copies your data to S3. Your job would then need to know where to pick up the payload in the cloud, how to copy it down to the local EC2 instance and do its computing and then where to send it. Finally, you’d need something to copy that data back to your on-premise datacenter for inspection. The complexity of the task mostly depends upon how complicated and flexible your workflows are as well as the availability and willingness of the group which owns the workflow to refactor.
One approach is to use a third party solution to synchronize the data for you. There are many such products out there. Some of them are tied to specific on-premise storage solutions such as Netapp or Dell/EMC while other companies offer a more independent method such as Weka.io or IC Manage PeerCache. Such solutions offer intriguing and potentially easy ways to create a workable hybrid solution if you are using small files, but be warned that if you have files that are hundreds of gigabytes or more in size, you could see unpredictable results in your applications as those files upload in the background. A third option is AWS DataSync. However, it is really geared to move your data into AWS but not to synchronize it back to your on-premise source.
- Data in is free, data out will cost
Assuming that you conquer the data synchronization challenge and are able to seamlessly send your data up, do your computing, and then bring your results back, you will be faced with the next challenge — data egress charges.
If your results are very data intensive, you could easily pull down 25TB or more per month. At the current rates, pulling that much data from the Virginia region (us-east-1) would cost you $2,227.11. Here’s the cost breakout:
Internet: Tiered pricing for 25600 GB:
1 GB x 0 USD per GB = 0.00 USD
10239 GB x 0.09 USD per GB = 921.51 USD
15360 GB x 0.085 USD per GB = 1305.60 USD
Data Transfer cost (monthly): 2,227.11 USD
That’s $26,725.32 per year. You can easily estimate your cost with the AWS Pricing Calculator at https://calculator.aws.
It won’t take many monthly bills for your finance department to come knocking on your door to walk them line by line through the statement.
- Code refactoring
Regardless of the synchronization method you employ, you’ll ultimately have to refactor your workflows to take full advantage of the cloud. It could be something simple like submitting to a new queue. It could be more complicated such as having the workflow test to see if it is running on-premises or in the cloud and taking different actions based on the runtime environment. Even after re-creating your on-premises environment to the best of your ability, you are likely to find that you are missing key network dependencies you don’t even know you have.
- Hidden network dependencies
Many years ago I worked at an engineering company and we had an engineer leave. Per standard process, we archived that user’s home directory. Almost immediately the helpdesk phone started ringing off the hook. All their jobs were crashing! Something’s changed! After huddling in a war room for a couple of hours, we finally figured out that it was that archived home directory causing the problem. It had a small script that was vital and hard coded into the team’s workflow.
No one remembered they needed it and if we’d asked them if it was ok to archive the home directory ahead of time, they probably would have said ‘no problem’. The point is, if your environment is of sufficient age and complexity, you have network dependencies you need to find and replicate for a hybrid solution. Fortunately, there is a tool called Breeze from Ellexus software that will create a Bill of Materials of network dependencies for a given run.
Charting the path forward
Sit back and take a deep breath. Despite these challenges, there is a successful path forward with cloud – a path that offers tremendous flexibility, scalability and elasticity that is simply not possible with on premises solutions.
Resist the cloud burst urge and follow our workload-based approach to Computing at Scale; we recommend that you focus on a single SOMETHING at a time. That thing can be a workflow, a department, a function, or simply a repetitive but resource-intensive task. Narrow the scope to something manageable and plan to simply move its data to the cloud and run it there. When the task is complete, copy the data back if you don’t want to continue paying for the storage in the cloud long term.
NTT DATA can help you put the right analysis into determining which workloads to focus on first.
*This was originally written by Flux7 Inc., which has become Flux7, an NTT DATA Services Company as of December 30, 2019
Subscribe to our blog