



A Beginner’s Guide to Selecting Infrastructure for HPC on AWS
- April 21, 2020
If you are an HPC administrator and you’ve recently been asked to look at how you can take advantage of HPC on AWS, you may have opened an account and been confronted with this:

There are a LOT of choices available when you log in to AWS. On the one hand, that’s exciting because there are likely some things there that you don’t have available in your on-premises datacenter. On the other hand, it can be intimidating and time-consuming to narrow down your choices into something that will meet your technical and budgetary needs. Not to be alarmist, but a wrong choice could lead to unnecessary cost overruns or scalability issues. This guide is meant to help you cut to the chase on some key options.
At its heart, HPC on AWS requires a few components: Compute, Storage, Networking, and Infrastructure. Let’s walk through each.
AWS Compute
At the time of writing, AWS offers 266 instance types and size combinations. For example, a c5.large has 2 VCPUs (hyperthreaded CPUs, so 1 physical core) and 4GB of RAM. A c5.24xlarge has 96 VCPUs and 192GB of RAM. Same CPU model underneath, just different core counts and memory sizes.
Decoding Instance Names
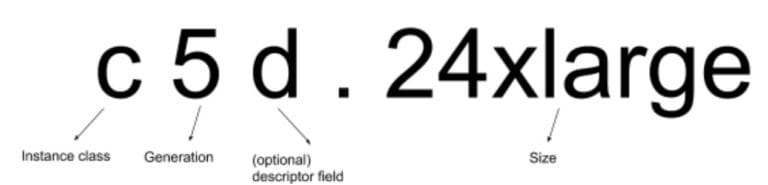
In AWS nomenclature, the first letter is the instance class, and it gives you a clue as to its purpose in life.
The number is what generation of the class it is. The higher, the newer. At the time of this writing, the highest generation available for most classes is 5.
The optional descriptor field gives you information on a special hardware characteristic of the instance type. For example, a “d” typically indicates a local disk drive (also called ephemeral storage). While an “n” indicates additional networking capabilities. And the “a” signifies that it is an AMD-based processor rather than Intel. A “g” means it is the AWS-proprietary Graviton processor. An instance with “metal” at the end is just what you think it is — a bare-metal instance without a hypervisor at all.
The size field is a little tricky at times. The t series machines include things like micro and nano. However, the c series lists everything as some kind of “large”. Generally, all you need to know is that the larger the size, the greater the number of CPUs, RAM and network bandwidth you will have available.
| Class | Defining Characteristic | GB RAM per physical core | Max Network throughput |
| C | Compute Optimized | 4 | 25 Gbps |
| M | General Purpose Compute | 8 | 25 Gbps |
| R | Memory Optimized | 16 | 25 Gbps |
| X | large-scale in-memory applications | 30.5 | 25 Gbps |
In general, HPC shops are going to care the most about the following instance families: C, M, R, and X. You will see many examples of people testing things on t2.micro instances in particular. They are very popular because they are very cheap and fall into the “free tier” of usage. You should NEVER run production workloads on a t series instance because they are essentially “spare cycles” of other servers and have CPU and network rate limits on them.
AWS Storage
AWS has many native storage options from which to choose. Each has its strengths and weaknesses.
Network Storage
If you need POSIX-compliant filesystems, AWS has two native offerings for you. EFS (the Elastic File System) and FSx for Lustre.
EFS
EFS is a managed, NFSv4 filesystem with high durability and resiliency. Its implementation spans multiple Availability Zones within a single region, which is what gives it its good durability. However, that durability hampers its write throughput.
EFS will scale performance based on the amount of data in a filesystem. You can also get “provisioned throughput” for an extra charge. It is a fine filesystem if you have read-only data that needs to be in a POSIX filesystem. Be sure to use the Max IO setting when you create a filesystem if you intend to use it as such.
When you create a filesystem and mount it, you will see that the filesystem size is 2 EXABYTES. By far one of the biggest advantages of EFS is the fact that you will probably never have to worry about running out of space and you only get charged for what you use, not the provisioned amount of storage.
FSx for Lustre
This is the “new kid on the block” in the AWS storage suite. It is a managed Lustre filesystem, which is great because Lustre is notoriously difficult to manage. FSx for Lustre really shines as a scratch filesystem. While AWS has recently added more durability to the filesystem, its roots are not that durable. Under the covers, I suspect that AWS is spinning up EC2 instances with local NVMe drives to store and serve the data in a mesh. This had recently meant that if a node was lost in the mesh that your filesystem was corrupt and you had to start over again. The latest news is that AWS can handle a failure or two, but it is still nowhere near as durable as EFS.
The original use model AWS suggested with FSx was to create a filesystem (which must be created in 1.2, 2.4 or 3.6 TB chunks and cannot be changed after creation), use it, and then destroy it when you are done. It was not touted as a durable filestore in the way EFS is. Recently, AWS has added an option for more persistent storage on FSx, along with many other enhancements. You can see the full set of expanded features in this blog post: https://aws.amazon.com/blogs/aws/amazon-fsx-for-lustre-persistent-storage/
Third Party Options
There are many third party storage solutions out there. Netapp Cloud Volumes, weka.io, and IC Manage Peer Cache, among others. If you have a dominant vendor on-premises and are looking for a way to flex out to the cloud, I can guarantee that they have a solution for you. While I cannot vouch for the efficacy of those solutions, it would probably be worth talking to them if you are looking for an integrated solution for data migration and synchronization.
AWS Networking
There are some key considerations to take into account on the networking front. Most of them have to do with the level of coupling your applications have and how much dedicated bandwidth you need.
Bandwidth and Instance Type Selection
Smaller instance types have less dedicated network bandwidth to them. And if you think about it, that makes sense. A smaller instance type is a smaller slice of a physical machine, and AWS could fill that physical machine up with other tenants, each wanting some amount of network bandwidth. However, if you get a “big” instance type that essentially takes up the entire machine, then you get the entire machine’s bandwidth to yourself.
Placement Groups
If your workloads need high speed, low latency networking for communication protocols, you will want to utilize a placement group. A placement group gives you options to have EC2 instances placed locally in the same Availability Zone to minimize latency. It’s beyond the scope of this document to detail everything about those, but be aware that AWS gives you tools to minimize latency between EC2 instances.
Elastic Fabric Adapter (EFA)
If your workloads utilize MPI and that’s been a blocker for adopting AWS in the past, you need to check out EFA. You can attach these adapters to c5n.18xlarge and p3dn.24xlarge instance types and linearly scale your MPI performance across hundreds or thousands of nodes. You can learn more about EFA on the AWS website: https://aws.amazon.com/hpc/efa/
Accelerated Computing Options
AWS has several options to enable accelerated computing.
- Firstly they have their GPU-enhanced instance type, the p3, which supports up to 8 NVIDIA Tesla V100 GPUs, each pairing 5,120 CUDA Cores and 640 Tensor Cores.
- Next up is the Inf1, which is custom silicon from AWS to support machine learning inference applications.
- The G4 series sports up to 8 NVIDIA T4 Tensor Core GPUs.
Finally, the F1 instance type offers instances with Field Programmable Gate Arrays (FPGA). While these require you to know the language to program the FPGA, it offers an extremely fast computing option where you essentially “program” at the hardware level.This guide was meant to help you focus on the (relatively) smaller set of AWS services that matter to most HPC shops. If you are at the beginning of your HPC on AWS journey and looking for a trusted partner to help guide you through these decisions in a more personalized way, reach out today. We bring experience with hundreds of AWS projects across HPC and a wide variety of cloud technologies such as infrastructure as code to help you successfully take advantage of the elasticity, scalability, and flexibility that the cloud has to offer.
Subscribe to our blog